Networked Systems
I have designed, built and deployed on the Internet prototypes of several novel networked systems, each with specific demands and challenges.
1. AntMonitor: A System for Monitoring from Mobile Devices
Mobile devices play an essential role in the Internet today, and there is an increasing interest in using them as a vantage point for network measurement from the edge. At the same time, these personal devices store a lot of sensitive information, and there is a growth in the number of applications that leak it. We propose AntMonitor – the first system of its kind that (i) supports collection of large-scale, semantic-rich network traffic in a way that respects users’ privacy preferences and (ii) supports detection and prevention of leakage of private information in real time. The first property makes AntMonitor a powerful tool for network researchers who want to collect and analyze large-scale yet fine grained mobile measurements. The second property works as an incentive for users to use AntMonitor and contribute data for analysis. As a proof-of-concept, we have developed a prototype of AntMonitor and deployed it to monitor users for 2 months. We successfully collected and analyzed 20 GB of mobile data from 151 applications. Preliminary results show that fine-grained data collected from AntMonitor could enable application classification with higher accuracy than state-of-the-art approaches. In addition, we demonstrated that AntMonitor could help prevent several apps from leaking private information over unencrypted traffic, including phone numbers, emails, and device identifiers.
AntMonitor is available in Google Play for alpha testing. Please contact me if you are interested in participating in our research study.
What is AntMonitor?
Publications
- A. Shuba, A. Le, M. Gjoka, J. Varmarken, S. Langhoff, A. Markopoulou, "AntMonitor: A System for Mobile Traffic Monitoring and Real-Time Prevention of Privacy Leaks,” ACM Mobicom Demo, Paris, France, Sep 7-10, 2015.
- A. Shuba, A. Le, M. Gjoka, J. Varmarken, S. Langhoff, A. Markopoulou, "Demo: AntMonitor - Network Traffic Monitoring and Real-Time Prevention of Privacy Leaks in Mobile Devices," ACM S3 Workshop on Mobile Computing and Networking, Paris, France, Sept. 2015. (Best Demo Award Winner)
- A. Le, J. Varmarken, S. Langhoff, A. Shuba, M. Gjoka, A. Markopoulou, "AntMonitor: A System for Monitoring from Mobile Devices," accepted to ACM SIGCOMM Workshop on Crowdsourcing and Crowdsharing of Big Internet Data (C2BID), London, UK, Aug. 17, 2015.
Patents
Under submission
2. QuestCrowd: A location-based question answering system with participation incentives
QuestCrowd is a system that uses crowd-sourcing to answer simple day-to-day questions tied to a specific location. It supports realtime questions, e.g. "How crowded is Laguna Beach right now?", along with questions that can be answered using factual information by people not present at the location, e.g. "Is there street parking available around Honda Center at Anaheim, California?" . Key design mechanisms that set it apart from similar location-based systems include (i) a reputation system that motivates quality contributors by rewarding high quality answers, and (ii) a forwarding mechanism that leverages existing social graph relations to increase participation.
Publications
- V.S.K. Pulla, C.S. Jammi, P. Tiwari, M. Gjoka, A. Markopoulou, "QuestCrowd: A location-based question answering system with participation incentives", IEEE INFOCOM '13 Posters Session

3. Social Graph Crawler
I built a Social Graph Crawler to tackle technical challenges faced during data collection in large-scale Online Social Networks. The crawler (i) operates in rich content websites, (ii) implements several principled sampling methods and (iii) performs distributed data fetching primarily to reduce the effect of user growth in the collected sample and secondarily to bypass data access limitations. More importantly, the crawler allowed me to perform network measurements on real large-scale graphs, such as Facebook, and Last.fm, and collect user profile information for tens of millions of users.
Publications
- M. Gjoka, M. Kurant, C. Butts, A. Markopoulou, "Practical Recommendations on Crawling Online Social Networks", in IEEE JSAC on Measurement of Internet Topologies, Vol.29, No. 9, Oct. 2011.
- M. Gjoka, C.T. Butts, M. Kurant, A. Markopoulou, "Multigraph Sampling of Online Social Networks", in IEEE JSAC on Measurement of Internet Topologies, Vol. 29, No. 9, Oct. 2011
- M. Gjoka, M. Kurant, C.T. Butts, A. Markopoulou, "Walking in Facebook: A Case Study of Unbiased Sampling of OSNs", IEEE INFOCOM 2010
| Dataset | Sampling Method | # Samples |
|---|---|---|
| Breadth First Search | 2.2M users | |
| Random Walk | 2.2M users | |
| Uniform | 1M users | |
| Metropolis Hastings | 1M users | |
| S-Weighted Random Walk | 1M users | |
| Complete Sample | 16K apps | |
| Uniform Egonets | 5.6M users 36K egonets |
|
| Last.FM | Uniform | 500K users |
| Random Walk - Friends | 250K users | |
| Random Walk - Events | 250K users | |
| Random Walk - Groups | 250K users | |
| Random Walk - Neighbors | 250K users | |
| Random Walk - Multigraph | 250K users |
4. Aball: crowdsourcing made easy
Adball is a company that I co-founded and directed as the CTO. It provides an online collaboration and social networking platform that crowd-sources the concept, content generation, and dissemination of advertising campaigns. It brings order to the crowd-sourced creative process, by (i) organizing the collaboration among its users, (ii) enabling a multi-staged collaborative process, (iii) ranking the produced content, and (iv) assigning reputations to users based on their interactions within the platform. Adball won two entrepreneurship awards and served approximately 20K users during its five month online presence.
What is Adball?
5. Kangaroo: Video Seeking in P2P Systems
Kangaroo is a scalable peer-to-peer Video-on-Demand streaming system that supports forward and backward seeking, built in collaboration with Telefonica Research. Using key mechanisms, algorithms, and data structures at the peers (neighborhood manager, scheduler) and tracker (scalable smart tracker), Kangaroo supports seeking operations without the need for over-provisioned peers or server. We evaluated its performance in a wide area network during the 2008 Olympics and accomplished technology transfer to Telefonica. Kangaroo won the New Internet Application (NAI) 2007 award in Spain.
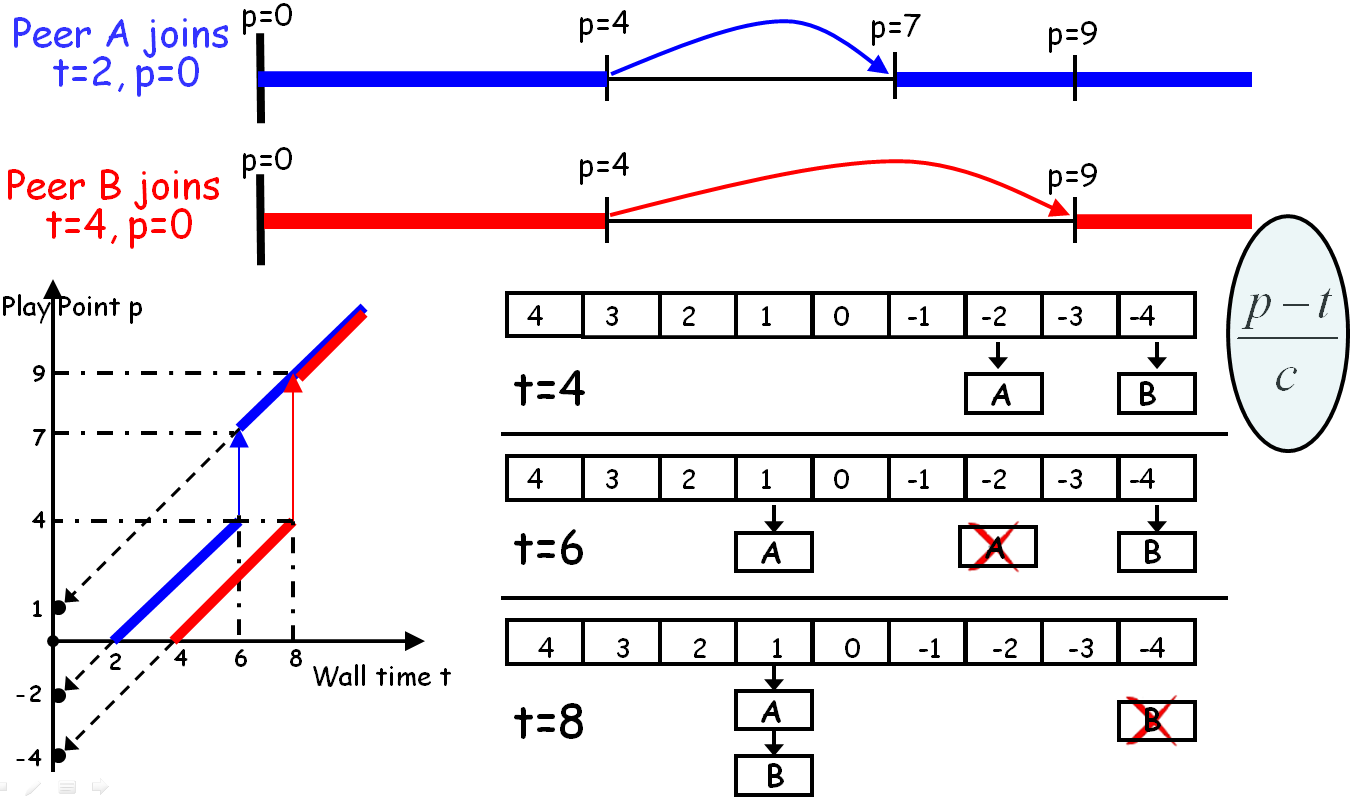
Playback neighbor selection at Tracker

History neighbor selection at Tracker

Hybrid segment scheduling policy in Kangaroo achieves "Seed Load" as low as ideal P2P
Publications
- X. Yang, M. Gjoka, P. Chhabra, A. Markopoulou, P. Rodriguez, "Kangaroo: Video Seeking in P2P Systems", in Proc. of USENIX IPTPS, Boston, April 2009.
- X. Yang, M. Gjoka, A. Markopoulou, P. Rodriguez, "Understanding the impact of VCR operations in P2P VoD systems", Technical Report, November 2007
Patents
Sampling and Analysis of Massive Online Graphs
Graphs are a common way to represent internet systems and the data produced by them. Some examples include social, web, email, and peer-to-peer graphs. In many cases, these graphs are difficult to study because of their massive size or access/collection limitations. Therefore, network-based sampling is required to estimate the properties of such graphs as a step towards understanding them. In this research work, I have addressed questions on how to collect (sampling methodologies) and use (estimation and analysis) a representative sample of a massive graph using network-based sampling.
1. Statistically principled sampling methods
-
We advocated the use of statistically principled methods, whose bias can be corrected, in the measurement of social graphs. Our work demonstrated in a real social graph (Facebook) that common sampling methods that were previously used by the network measurement community, such as Breadth-First-Search, are significantly biased and skew the estimation of local and global graph properties despite a seemingly large sample size. For unbiased estimation, we proposed two random walk-based sampling methods and provided trade-offs and suggestions for their use. Additionally, we used formal convergence diagnostics to assess sample quality during the data collection process.

Breadth First Search is biased compared to the ground truth (UNI)

Reweighted Random Walk
provides unbiased estimation
Convergence of random walks to
true value of average degree
-
We proposed a novel random walk-based sampling method, Stratified Weighted Random Walk (S-WRW), which takes into account the node properties that are relevant to the measurement objective when setting edge weights during the network sampling. An experimental evaluation in the Facebook social graph shows that a Stratified Weighted Random Walk needs up to 15 times less samples than a simple Random Walk to achieve the same error for the estimation of the college sizes in the Facebook social graph.
-
We proposed a novel random walk-based sampling method, Multigraph Sampling, which exploits the existence of multiple relation graphs defined on the same set of nodes in the graph. For example, in social graphs, in addition to the friendship relation, one can consider the group membership or event participation relation. Multigraph Sampling obtains a representative sample with faster convergence, even when the individual graphs fail, i.e. are disconnected or highly clustered. Additionally, we designed a computationally efficient algorithm that practically implements Multigraph Sampling as a union of individual graphs.

Measurement Error of our method (S-WRW) and of a Random Walk as a function of number of samples

Overview of Stratified Weighted Random Walk

Estimation of percentage of paid subscribers in Last.FM is very accurate with Multigraph Sampling
Publications
- M. Gjoka, M. Kurant, C. Butts, A. Markopoulou, "Practical Recommendations on Crawling Online Social Networks", in IEEE JSAC on Measurement of Internet Topologies, Vol.29, No. 9, Oct. 2011.
- M. Kurant, M. Gjoka, C.T. Butts, A. Markopoulou, "Walking on a Graph with a Magnifying Glass: Stratified Sampling via Weighted Random Walks", SIGMETRICS 2011
- M.Gjoka, C.Butts, M.Kurant, A.Markopoulou, "Multigraph Sampling of Online Social Networks", in IEEE JSAC on Measurement of Internet Topologies, Vol. 29, No. 9, Oct. 2011
- M.Gjoka, M.Kurant, C.Butts, A.Markopoulou, "Walking in Facebook: A Case Study of Unbiased Sampling of OSNs", IEEE INFOCOM 2010
2. Estimation and analysis in massive graphs
My research has shown how to properly perform unbiased estimation of graph properties that reveal information about the network structure using a sample of nodes, under a variety of probabilistic sampling techniques (independence sampling and random walks) and designs (induced sampling and star sampling). I have collected some of the first representative samples from large online social networks (Facebook and Last.fm) and made them publicly available to researchers. The samples consist of millions of users and their neighbors and have been requested more than 3,000 times by researchers and students in various universities and research institutes.
- In Facebook, we characterized key topological properties of the social graph (node degree distribution, the degree-dependent clustering coefficient, and assortativity) and user privacy awareness conditioned on geography, degree and neighbor's privacy awareness.
- In Last.fm, we estimated properties of the relation graphs that comprised the multigraph (friendship, group and event membership) and general properties of the website such as the percentage of paid subscribers and the weekly music charts.
- We designed unbiased estimators that count the frequency of subgraphs (or motifs) within a potentially unknown graph through egocentric graph sampling. We have generalized our estimators to count subgraphs in which nodes have attributes or edges are directed. Additionally, we present two types of unbiased estimators, one of which exploits labeling of sampled nodes neighbors and one of which does not require this information. Simulation shows that our method outperforms the state-of-the-art approach for relative subgraph frequencies by up to an order of magnitude for the same sample size. Finally, we apply our methodology to an egocentric sample of 36K users across the Facebook social graph to estimate and interpret the clique size distribution and gender composition of cliques.
- We derived novel estimators of the degree-dependent clustering coefficient and joint degree distribution. The estimation of such graph properties can be used as an input to network models that generate synthetic graphs resembling the real graph.
- We derived estimators that summarize the social graph of an online social network as a category graph. For example, we can use the friendship of users in Facebook that live in different countries to summarize the strength of social relationships between any two countries as a country-to-country category graph. We then designed a web-based visualization tool, GeoSocialMap, that aims to visually represent category graphs embedded in geography and is well suited for data exploration.
- We were the first to study the popularity and user reach of Facebook applications. Based on user application installation statistics obtained by crawling Facebook, we proposed a simple and intuitive model to simulate the process with which users install Facebook applications. Using this model one can determine the user coverage from the popularity of applications, without detailed knowledge of how applications are distributed among users. Such prediction can be useful to parties interested in reaching users via applications.

Estimation of Weekly Last.FM charts using crawled data.
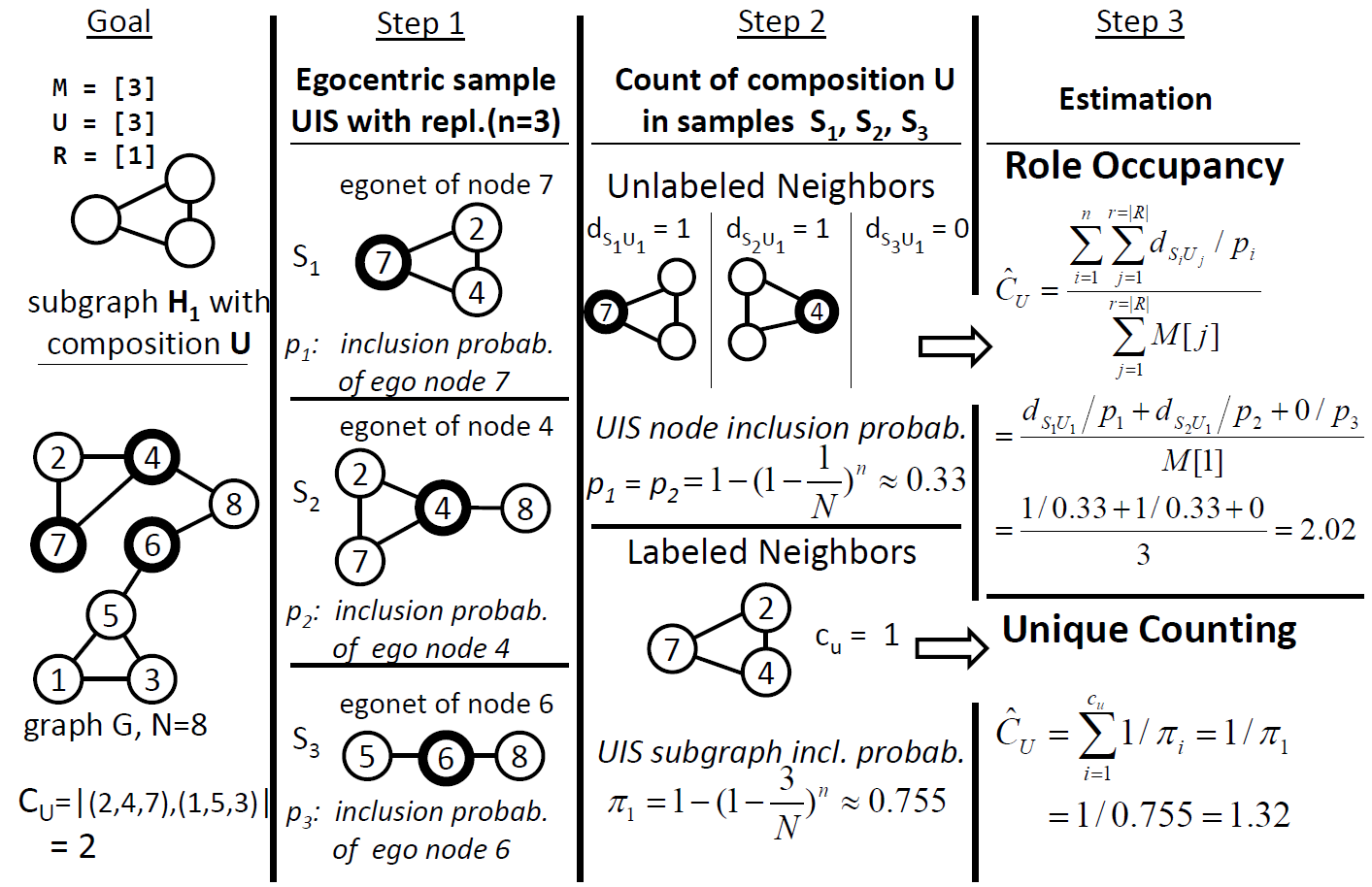
Illustration of proposed subgraph count estimation methods
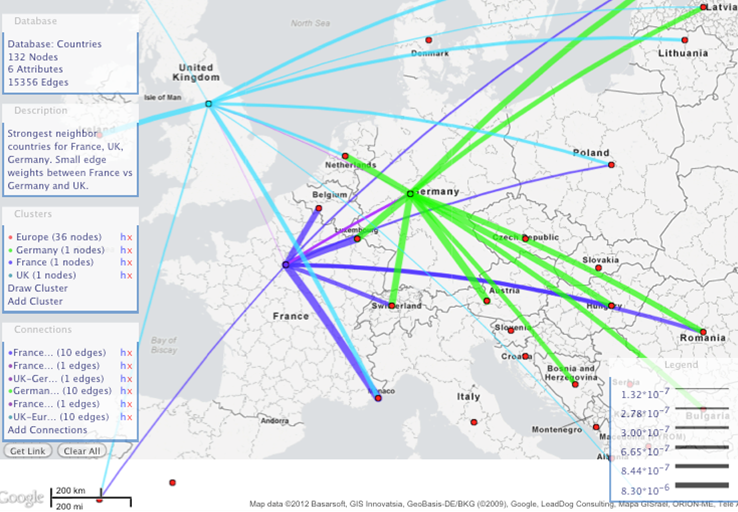
Visualization of strongest neighbors for France, Germany, UK within Geosocialmap
Publications
- M. Gjoka, E. Smith, C.T. Butts, "Estimating Subgraph Frequencies with or without Attributes from Egocentrically Sampled Data", arXiv:1510.08119, October 2015
- M. Gjoka, E. Smith, C.T. Butts, "Estimating Clique Composition and Size Distributions from Sampled Network Data", IEEE NetSciCom 2014
- M. Gjoka, M. Kurant, A. Markopoulou, "2.5K-Graphs: from Sampling to Generation", IEEE INFOCOM 2013
- M. Kurant, M. Gjoka, Y. Wang, Z.W. Almquist, C.T. Butts, A. Markopoulou, "Coarse-Grained Topology Estimation via Graph Sampling", ACM SIGCOMM Workshop on Online Social Networks 2012
- M. Gjoka, M. Kurant, C. Butts, A. Markopoulou, "Practical Recommendations on Crawling Online Social Networks", in IEEE JSAC on Measurement of Internet Topologies, October 2011.
- M. Gjoka, C.T. Butts, M.Kurant, A.Markopoulou, "Multigraph Sampling of Online Social Networks", in IEEE JSAC on Measurement of Internet Topologies, October 2011
- M. Kurant, M. Gjoka, C.T. Butts, A. Markopoulou, "Star Sampling and its Application to Online Social Networks", Network Mapping and Measurement Conference 2011,
- M. Kurant, M. Gjoka, C.T. Butts, A. Markopoulou, "Walking on a Graph with a Magnifying Glass: Stratified Sampling via Weighted Random Walks", SIGMETRICS 2011
- M. Gjoka, M. Kurant, C.T. Butts, A. Markopoulou, "Walking in Facebook: A Case Study of Unbiased Sampling of OSNs", IEEE INFOCOM 2010
- M. Gjoka, M. Kurant, C.T. Butts, A. Markopoulou, "A Walk in Facebook: Uniform Sampling of Users in Online Social Networks", arXiv:0906.0060, May 2009
- M. Gjoka, M. Sirivianos, A. Markopoulou, X. Yang, "Poking Facebook: Characterization of OSN Applications", ACM SIGCOMM Workshop on Online Social Networks 2008
Graph Construction Algorithms
1. 2K+ algorithms
We developed a class of algorithms that constructs simple graphs with a desired joint degree matrix (JDM) and possibly additional properties. First, we presented 2K_Simple, an algorithm that provably constructs simple graphs with an exact JDM target, in approximately linear time in the number of edges. We showed that 2K_Simple has increased flexibility in selecting edges compared to prior approaches, which we then exploit to impose additional structure on top of the JDM, still in approximately linear time. 2K_Simple_Clustering targets exact JDM and approximate degree-dependent average clustering coefficient. 2K_Simple_Attributes targets exact JDM and joint occurrence of node attribute pairs. We demonstrated through simulations the potential of our algorithms in generating graphs resembling real-world social networks fast; the construction time for a set of Facebook topologies is reduced from days to 10s of seconds. A reference implementation of 2K_Simple is available in both Python and C++.

2K_Simple: Neighbor switches that guarantee construction of a simple graph with a given joint degree matrix
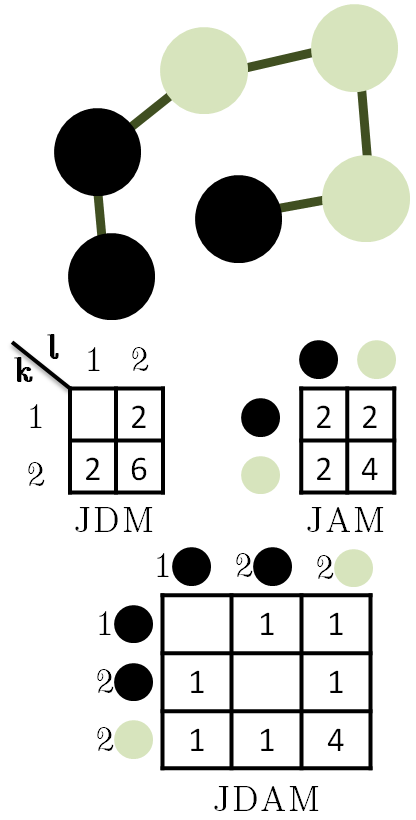
2K_Simple_Attributes: generates a graph with given JDAM

2K_Simple_Clustering: Control average clustering by controlling the order of node pairs during graph construction
Publications
- M. Gjoka, B. Tillman, A. Markopoulou, "Construction of Simple Graphs with a Target Joint Degree Matrix and Beyond", IEEE INFOCOM 2015
- M. Gjoka, B. Tillman, A. Markopoulou, R. Pagh, "Efficient Construction of 2K+ Graphs", NetSci 2014
2. Construction of 2.5K Graphs
We developed a model that builds on the dK-series framework and can be used to generate synthetic graphs with key properties resembling those of a real yet not fully known graph. The model, named 2.5K graph, exactly specifies joint degree matrix (or degree correlations) and clustering. It is shown to be a sweet spot between accurate representation of the original graph and practical constraints. We showed how to estimate the model parameters by sampling the graph and presented new algorithms that efficiently generate synthetic graphs with the specified model parameters. In simulations our approach was shown to be orders of magnitudes faster than prior approaches.

Overview of 2.5K-Graph construction
Publications
- M. Gjoka, M. Kurant, A. Markopoulou, "2.5K-Graphs: from Sampling to Generation", IEEE INFOCOM 2013
Smart cities
We presented an approach that infers features of urban ecology (i.e., the distribution of population density, social and economic activities, and social interaction) from spatiotemporal cell phone activity data. The key to our approach is the spectral decomposition of the original cell phone activity series into seasonal communication series (SCS) and residual communication series (RCS). The RCS and SCS provide distinct probes into the structure and dynamics of the urban environment, both of which can be obtained from the same underlying data. We applied our methodology to aggregate Call Description Records (CDRs) from the city of Milan.
Video of heatmap activity for 24h in Milan, Italy during Nov. 1st 2013
SCS captures regular patterns of socio-economic activity within an area. We showed how to use SCS to segment the city of Milan into distinct clusters but also to discover regions whose activity patterns differ markedly from the rest of the city (e.g. the San Siro stadium and Otomercato). Also, we showed that the results compare favorably with state-of-the-art approaches since SCS is able to flexibly and parsimoniously incorporate regular patterns occurring on any time scale. RCS across areas enables the detection of regions that are subject to mutual social influence and of regions that are in direct communication contact. Segmentation of the city based on cross-correlation between the RCS time series of grid squares yields a different result from that obtained by SCS (e.g. the center of the city and the Milano Linate airport are separated from the rest of the squares). Finally, we showed that RCS correlations between areas are significantly related to the volume of inter-area cell phone traffic in the city of Milan.

Difference in mobile phone activity time series for a university and a stadium (San Siro) grid square in Milan (11/4/2013-11/10/2013)
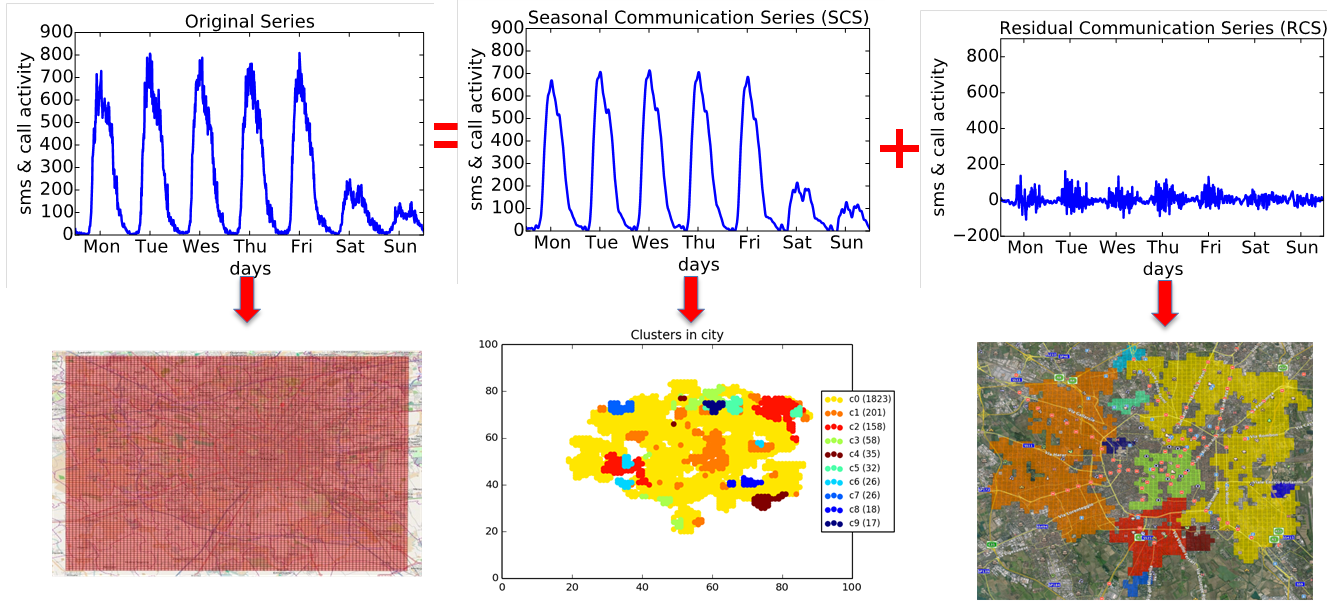
Overview of our decomposition approach and the result of clustering of grid squares in the city of Milan according to their activity time series
Publications
- B. Cici, M. Gjoka, A. Markopoulou, C.T. Butts, "On the decomposition of cell phone activity patterns and their connection with urban ecology", ACM MobiHoc '15
Network Security
Denial-of-service attacks pose a real threat in the operation of computer networks. They typically exhaust resources and disrupt the normal operation of a target network host or subnet. In this area, I identified new attacks that can leverage the traffic produced by peer-to-peer systems and improved the traceback of attack sources.
1. Preventing misuse of peer-to-peer systems
We identified vulnerabilities in the design of BitTorrent that can be exploited to use the system as a platform for launching denial-of-service attacks to hosts outside the peer-to-peer swarm. We measured and characterized the attack traffic from live Internet experiments that demonstrate the feasibility of such attacks. Our insights received publicity from the New Scientist and Slashdot.
Publications
- K. El Defrawy, M. Gjoka, A. Markopoulou, "BotTorrent: Misusing BitTorrent to Launch DDoS Attacks", USENIX Steps Towards Reducing Unwanted Traffic on the Internet 2007
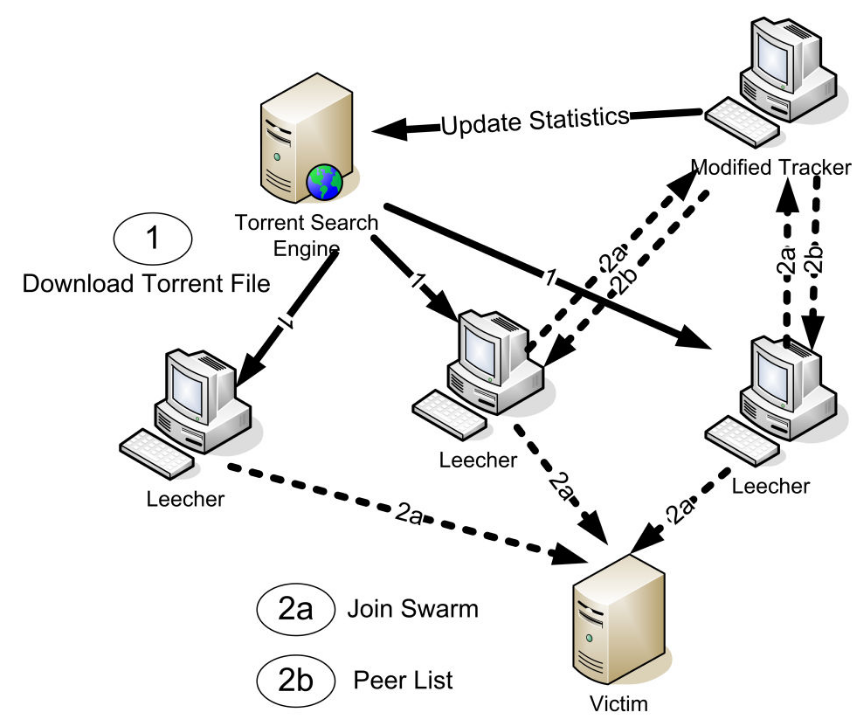
Misusing BitTorrent to generate a DDoS attack
2. IP traceback with network coding
We designed a practical IP traceback scheme that combines probabilistic packet marking with network coding. The purpose of a traceback scheme is to identify the source and node traversal path of the traffic. Inspired by the coupon collector's problem we mark packets with random linear combinations of router IDs, instead of individual IDs, so as to reduce the number of packets required to reconstruct the attack path and the total traceback time.
Publications
- P. Sattari, M. Gjoka, A. Markopoulou, "A Network Coding Approach to IP Traceback", IEEE NetCod 2010
- P. Sattari, M. Gjoka, A. Markopoulou, "A Network Coding-Based Approach to Probabilistic Packet Marking", Technical Report, December, 2008

Practical PPM+NC with 8-bit linear combination, 2-bit offset, k = 3, 2-bit coefficients, and 1-bit distance
Network Measurement
1. Network tomography
We developed new techniques to infer loss rates of individual network links of a network topology, by sending and collecting probe packets at the edge of a network that supports network coding, such as wireless networks, peer-to-peer networks and overlay networks. This is the first work in network tomography that leverages network coding capabilities, i.e. allows intermediate nodes to process and combine, in addition to just forward, packets. Our techniques improve estimation accuracy, bandwidth efficiency and link identifiability.
Publications
- P. Sattari, A. Markopoulou, C. Fragouli, M. Gjoka, "A Network Coding Approach to Loss Tomography", IEEE Transactions on Information Theory, 2013
- Minas Gjoka, Christina Fragouli, Pegah Sattari, Athina Markopoulou, "Loss Tomography in General Topologies with Network Coding", IEEE GLOBECOM 2007

Result of orientation algorithm for Abilene Internet topology.
2. IP Fast Re-Routing
With the increasing demand for low-latency applications in the Internet, the slow convergence of the existing routing protocols is a growing concern. A number of IP fast reroute mechanisms have been developed by the IETF to address the issue. The goal of the IPFRR mechanisms is to activate alternate routing paths which avoid micro loops under node or link failures. In this work, we present a comprehensive analysis of IP fast reroute proposals by evaluating their coverage for a variety of inferred and synthetic ISP topologies.
Publications
- M. Gjoka, V. Ram, X. Yang, "Evaluation of IP Fast Reroute Proposals", IEEE COMSWARE 2007

Example of Loop Free Alternate mechanism activation during a node or link failure